 구성의 기술적 맹점")
IT 시스템을 운영하는 사람 중 HA(High Availability, 고가용성)라는 단어에 가슴 설레지 않는 사람은 없을 것입니다. “서버 한 대가 죽어도 서비스는 멈추지 않는다.” 얼마나 든든한 말인가요?
특히 최근 PostgreSQL 기반 오픈소스 DB 검토 기조와 맞물려, 비용 절감을 무기로 “우리 제품은 단 2 노드(Node) (Active Standby)만으로도 완벽한 자동 Fail over와 고가용성을 보장합니다”라고 광고하는 솔루션들을 자주 접하게 됩니다. 하지만 냉정하게 기술의 민낯을 들여다봐야 합니다.
2개 노드만으로 구성된 오픈소스 DB 시스템은 과연 구조적으로 안전할까요?
2개 노드만으로 구성된 오픈소스 DB HA 시스템은 과반수 합의 알고리즘을 충족할 수 없어 구조적으로 취약합니다. 결론부터 말씀드리면, 그것은 데이터의 무결성을 담보로 한 위험한 도박일 수 있습니다.
Split Brain: 1대1 대치 상황이 만드는 데이터 정합성 재앙
PostgreSQL 기반 오픈소스 DBMS 2노드 HA의 치명적인 허점을 이해하려면 먼저 Split Brain(스플릿 브레인) 현상을 알아야 합니다.
Split Brain은 장애 상황에서 두 서버가 동시에 자신을 Primary라고 판단해 서로 다른 데이터를 기록하는 현상입니다. 이는 데이터 정합성을 심각하게 훼손할 수 있는 대표적인 고가용성 장애 유형입니다.
Active Standby 구조에서는 오직 1대의 Primary(Active) 서버만 살아 움직이며 데이터를 써야 합니다. 그런데 어느 날 갑자기 두 서버 사이의 네트워크가 툭 끊기거나, 장애가 애매하게 발생하면 어떻게 될까요?
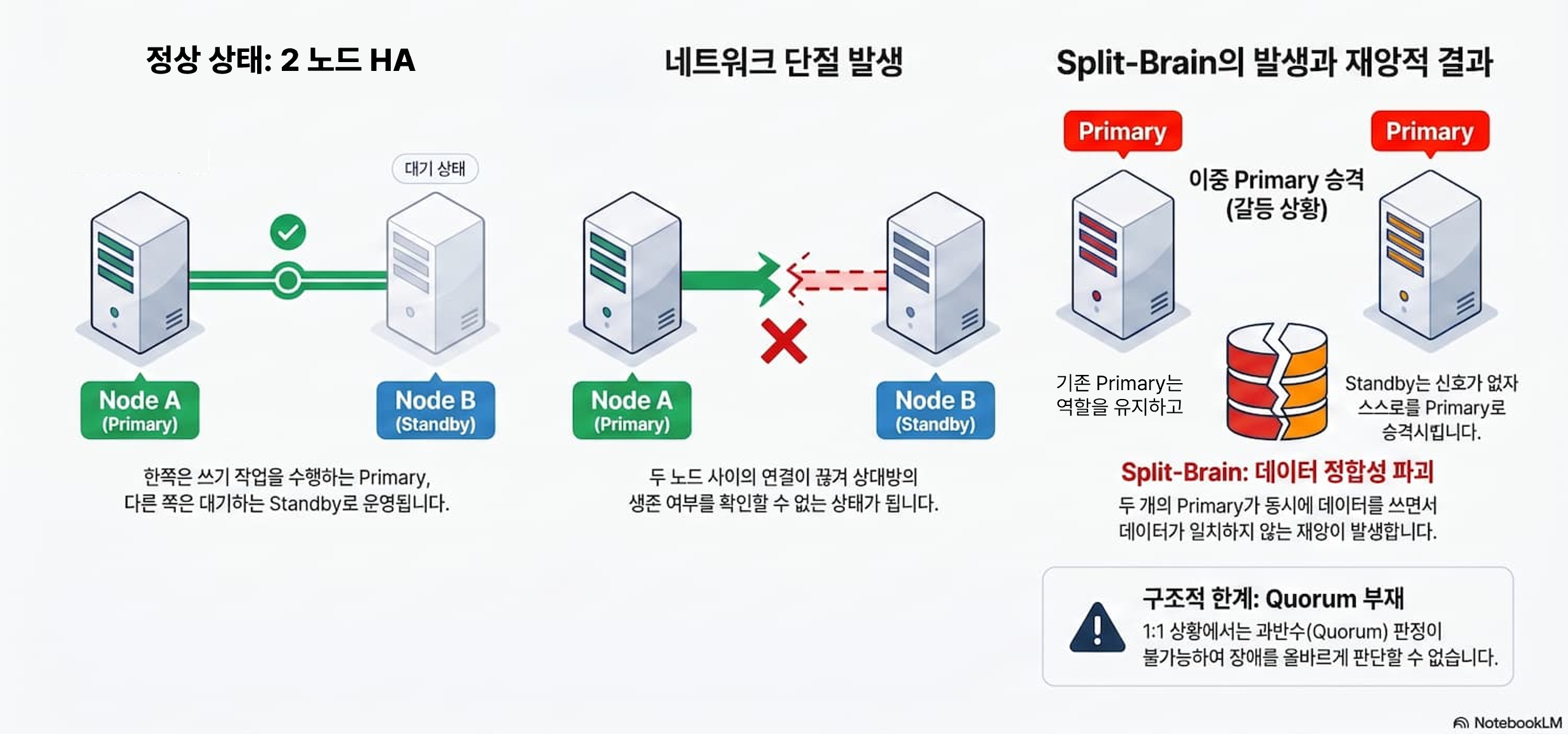
예를 들어 Primary와 Standby 간 네트워크가 갑자기 단절되었다고 가정해보겠습니다.
- 기존 Primary: “어? Standby랑 연락이 안 되네? 하지만 난 멀쩡히 살아있으니 계속 대장(Primary) 역할을 해야지.”
- 기존 Standby: “어? Primary한테서 신호가 안 오네? 죽었나 보다. 이제부터 내가 대장(Primary)이다!”
이렇게 되면 원래는 하나여야 할 대장이 순식간에 둘로 쪼개지는 Split Brain 상황이 벌어집니다. 이 순간부터 양쪽 서버에 같은 데이터가 서로 다르게 저장될 수 있게 되는 것입니다. 겉으로는 서비스가 살아 있는 것처럼 보여도, 내부적으로는 데이터가 사정 없이 깨지는 ‘최악의 데이터 정합성 훼손’이 발생합니다.
이후 데이터를 다시 하나로 통합하는 과정은 매우 어렵고, 경우에 따라서는 일부 데이터 손실을 감수해야 하는 상황까지 이어지며 그야말로 난이도가 급상승하는 재앙이 됩니다.
고가용성 확보를 위한 핵심 매커니즘
이러한 재앙을 막으려면 핵심은 하나입니다. “누가 진짜 죽었는지, 누가 살아남아야 하는지 제3의 기준으로 판정해야 한다”는 것입니다. 그래서 업계에서는 고가용성 시스템에 보통 세 가지 장치를 씁니다.
1. Witness (증인)
둘이 싸울 때 누가 맞는지 확인해 주는 제3자 역할입니다.
2. Quorum (정족수)
과반수 동의 개념으로, 정상적인 합의 판정을 위해 보통 최소 3개 투표권이 필요합니다.
3. Fencing (격리)
문제가 발생한 기존 Primary를 강제로 차단해 더 이상 쓰기 작업을 수행하지 못하도록 하는 안전장치입니다.
여기서 중요한 점은 Fencing은 격리 장치일 뿐, 판정 장치는 아니라는 것입니다.
Fencing은 중요하지만 격리 조치일 뿐, 판사가 아닙니다. 누가 살아남을지 결정하는 판정 체계(Witness/Quorum) 없이 Fencing만 있다고 해서 구조적으로 안전한 HA가 구현되는 것은 아닙니다.
그런데 단 2대의 노드만 있다면? 1대1로 싸우면 끝입니다. 누가 맞는지 과반수(Quorum) 판정이 안 됩니다. 네트워크 기반 복제(Replication)에 의존하는 일반적인 오픈소스 DB 환경에서는 이 판정 체계가 빠진 채 2노드만으로 완벽하고 안전한 HA를 보장하는 것이 구조적으로 어렵습니다.
즉, 오픈소스 DB 2노드 솔루션이 “자동 Fail-over가 되니 HA가 보장된다”고 주장하는 것은 ‘구성 가능’을 ‘보장 가능’으로 슬쩍 바꿔 말하는 과장된 메시지일 확률이 높습니다. 쉽게 말해 “브레이크 구조 설명은 없는데 차는 안전하다고 광고하는 것”과 비슷합니다.
오픈소스 DB HA의 정답: 데이터 무결성을 위한 ‘3노드 아키텍처’
결국 현장에서 시스템이 ‘단순 구동되는 것’과 ‘구조적으로 데이터의 정합성을 완벽히 보장하는 것’은 전혀 다른 영역의 이야기입니다.
오픈소스 기반 DB 환경에서 비즈니스의 핵심인 데이터를 안전하게 지켜내려면, 1대1의 대치 상황을 중재하고 과반수 투표권을 성립시켜 줄 제3의 노드가 반드시 추가되어야 합니다. 정상적인 합의형 장애 판정을 하려면 최소 3개의 투표권이 필요하기 때문입니다.
OpenSQL이 3노드 HA를 표준으로 채택한 이유
티베로가 제공하는 PostgreSQL 기반 DBMS인 OpenSQL을 구성할 때, 굳이 3노드 HA 아키텍처를 표준으로 채택한 이유가 바로 여기에 있습니다.
오픈소스 DB 환경에서도 상용 엔터프라이즈급의 완벽한 데이터 무결성과 고가용성(HA)을 제공하기 위해, 1대1 대립을 완벽하게 중재할 Quorum 체계를 아키텍처 관점에서 기본 탑재한 것입니다. 이를 통해 어떤 순간에도 Split Brain을 원천 차단하고 기업의 소중한 자산을 한 치의 오차도 없이 지켜냅니다.
결론: 진정한 HA는 ‘데이터 무결성’까지 보장해야 한다
진정한 HA 도입을 검토 중이라면, 단순히 “자동 Fail-over가 지원되는가?”라는 질문을 넘어 다음의 두 가지를 반드시 확인하세요.
-
Split Brain을 원천 차단할 제3의 판정 체계(Witness/Quorum)가 구조적으로 존재하는가?
-
구성만 가능한 것인가, 아니면 데이터 무결성을 100% ‘보장’하는 엔터프라이즈급 아키텍처인가?
가장 완벽한 HA는 서비스를 ‘이어 달리기’ 하는 것이 아닙니다. 서비스가 연속되는 그 순간에도 데이터가 100% 무결함을 구조적으로 보장받는 것, 그것이 OpenSQL의 3노드 아키텍처가 증명하는 진짜 고가용성의 가치입니다.
Other Articles
 구성의 기술적 맹점")
 구성의 기술적 맹점")


No Comment! Be the first one.